В настоящей и нескольких следующих заметках мы рассмотрим математические модели случайных событий. Математическая модель - это математическое выражение, представляющее случайную величину. Для дискретных случайных величин это математическое выражение известно под названием функция распределения.
Если задача позволяет явно записать математическое выражение, представляющее случайную величину, можно вычислить точную вероятность любого ее значения. В этом случае можно вычислить и перечислить все значения функции распределения. В деловых, социологических и медицинских приложениях встречаются разнообразные распределения случайных величин. Одним из наиболее полезных распределений является биномиальное.
Биномиальное распределение используется для моделирования ситуаций, характеризующихся следующими особенностями.
- Выборка состоит из фиксированного числа элементов n , представляющих собой исходы некоего испытания.
- Каждый элемент выборки принадлежит одной из двух взаимоисключающих категорий, исчерпывающих все выборочное пространство. Как правило, эти две категории называют успех и неудача.
- Вероятность успеха р является постоянной. Следовательно, вероятность неудачи равна 1 – р .
- Исход (т.е. удача или неудача) любого испытания не зависит от результата другого испытания. Чтобы гарантировать независимость исходов, элементы выборки, как правило, получают с помощью двух разных методов. Каждый элемент выборки случайным образом извлекается из бесконечной генеральной совокупности без возвращения или из конечной генеральной совокупности с возвращением.
Скачать заметку в формате или , примеры в формате
Биномиальное распределение используется для оценки количества успехов в выборке, состоящей из n наблюдений. Рассмотрим в качестве примера оформление заказов. Чтобы сделать заказ клиенты компании Saxon Company могут воспользоваться интерактивной электронной формой и послать ее в компанию. Затем информационная система проверяет, нет ли в заказах ошибок, а также неполной или недостоверной информации. Любой заказ, вызывающий сомнения, помечается и включается в ежедневный отчет об исключительных ситуациях. Данные, собранные компанией, свидетельствуют, что вероятность ошибок в заказах равна 0,1. Компания хотела бы знать, какова вероятность обнаружить определенное количество ошибочных заказов в заданной выборке. Например, предположим, что клиенты заполнили четыре электронных формы. Какова вероятность, что все заказы окажутся безошибочными? Как вычислить эту вероятность? Под успехом будем понимать ошибку при заполнении формы, а все остальные исходы будем считать неудачей. Напомним, что нас интересует количество ошибочных заказов в заданной выборке.
Какие исходы мы можем наблюдать? Если выборка состоит из четырех заказов, ошибочными могут оказаться один, два, три или все четыре, кроме того, все они могут оказаться правильно заполненными. Может ли случайная величина, описывающая количество неправильно заполненных форм, принимать какое-либо иное значение? Это невозможно, поскольку количество неправильно заполненных форм не может превышать объем выборки n или быть отрицательным. Таким образом, случайная величина, подчиняющаяся биномиальному закону распределения, принимает значения от 0 до n .
Допустим, что в выборке из четырех заказов наблюдаются следующие исходы:
Какова вероятность обнаружить три ошибочных заказа в выборке, состоящей из четырех заказов, причем в указанной последовательности? Поскольку предварительные исследования показали, что вероятность ошибки при заполнении формы равна 0,10, вероятности указанных выше исходов вычисляются следующим образом:
Поскольку исходы не зависят друг от друга, вероятность указанной последовательности исходов равна: р*р*(1–р)*р = 0,1*0,1*0,9*0,1 = 0,0009. Если же необходимо вычислить количество вариантов выбора X n элементов, следует воспользоваться формулой сочетаний (1):

где n! = n * (n –1) * (n – 2) * … * 2 * 1 - факториал числа n , причем 0! = 1 и 1! = 1 по определению.
Это выражение часто обозначают как . Таким образом, если n = 4 и X = 3, количество последовательностей, состоящих из трех элементов, извлеченных из выборки, объем которой равен 4, определяется по следующей формуле:
Следовательно, вероятность обнаружить три ошибочных заказа вычисляется следующим образом:
(Количество возможных последовательностей) *
(вероятность конкретной последовательности) = 4 * 0,0009 = 0,0036
Аналогично можно вычислить вероятность того, что среди четырех заказов окажутся один или два ошибочных, а также вероятность того, что все заказы ошибочны или все верны. Однако при увеличении объема выборки n определить вероятность конкретной последовательности исходов становится труднее. В этом случае следует применить соответствующую математическую модель, описывающую биномиальное распределение количества вариантов выбора X объектов из выборки, содержащей n элементов.
Биноминальное распределение

где Р(Х) - вероятность X успехов при заданных объеме выборки n и вероятности успеха р , X = 0, 1, … n .
Обратите внимание на то, что формула (2) представляет собой формализацию интуитивных выводов. Случайная величина X , подчиняющаяся биномиальному распределению, может принимать любое целое значение в диапазоне от 0 до n . Произведение р X (1 – р) n – X представляет собой вероятность конкретной последовательности, состоящей из X успехов в выборке, объем которой равен n . Величина определяет количество возможных комбинаций, состоящих из X успехов в n испытаниях. Следовательно, при заданном количестве испытаний n и вероятности успеха р вероятность последовательности, состоящей из X успехов, равна
Р(Х) = (количество возможных последовательностей) * (вероятность конкретной последовательности) =
Рассмотрим примеры, иллюстрирующие применение формулы (2).
1. Допустим, что вероятность неверно заполнить форму равна 0,1. Какова вероятность того, что среди четырех заполненных форм три окажутся ошибочными? Используя формулу (2), получаем, что вероятность обнаружить три ошибочных заказа в выборке, состоящей из четырех заказов, равна
2. Допустим, что вероятность неверно заполнить форму равна 0,1. Какова вероятность того, что среди четырех заполненных форм не менее трех окажутся ошибочными? Как показано в предыдущем примере, вероятность того, что среди четырех заполненных форм три окажутся ошибочными, равна 0,0036. Чтобы вычислить вероятность того, что среди четырех заполненных форм не менее трех будут неправильно заполнены, необходимо сложить вероятность того, что среди четырех заполненных форм три окажутся ошибочными, и вероятность того, что среди четырех заполненных форм все окажутся ошибочными. Вероятность второго события равна
Таким образом, вероятность того, что среди четырех заполненных форм не менее трех окажутся ошибочными, равна
Р(Х > 3) = Р(Х = 3) + Р(Х = 4) = 0,0036 + 0,0001 = 0,0037
3. Допустим, что вероятность неверно заполнить форму равна 0,1. Какова вероятность того, что среди четырех заполненных форм менее трех окажутся ошибочными? Вероятность этого события
Р(X < 3) = P(X = 0) + P(X = 1) + P(X = 2)
Используя формулу (2), вычислим каждую из этих вероятностей:

Следовательно, Р(Х < 3) = 0,6561 + 0,2916 + 0,0486 = 0,9963.
Вероятность Р(Х < 3) можно вычислить иначе. Для этого воспользуемся тем, что событие X < 3 является дополнительным по отношению к событию Х> 3. Тогда Р(Х< 3) = 1 – Р(Х> 3) = 1 – 0,0037 = 0,9963.
По мере увеличения объема выборки n вычисления, аналогичные проведенным в примере 3, становятся затруднительными. Чтобы избегать этих сложностей, многие биномиальные вероятности табулируют заранее. Некоторые из этих вероятностей приведены рис. 1. Например, чтобы получить вероятность, что Х = 2 при n = 4 и p = 0,1, следует извлечь из таблицы число, стоящее на пересечении строки Х = 2 и столбца р = 0,1.

Рис. 1. Биномиальная вероятность при n = 4, Х = 2 и р = 0,1
Биномиальное распределение можно вычислить с помощью функции Excel =БИНОМ.РАСП() (рис. 2), имеющей 4 параметра: число успехов – Х , число испытаний (или объем выборки) – n , вероятность успеха – р , параметр интегральная , принимающий значения ИСТИНА (в этом случае вычисляется вероятность не менее Х событий) или ЛОЖЬ (в этом случае вычисляется вероятность точно Х событий).

Рис. 2. Параметры функции =БИНОМ.РАСП()
Для вышеприведенных трех примеров расчеты приведены на рис. 3 (см. также Excel-файл). В каждом столбце приведено по одной формуле. Цифрами показаны ответы на примеры соответствующего номера).

Рис. 3. Расчет биноминального распределения в Excel для n = 4 и p = 0,1
Свойства биномиального распределения
Биномиальное распределение зависит от параметров n и р . Биномиальное распределение может быть, как симметричным, так и асимметричным. Если р = 0,05, биномиальное распределение является симметричным независимо от величины параметра n . Однако, если р ≠ 0,05, распределение становится асимметричным. Чем ближе значение параметра р к 0,05 и чем больше объем выборки n , тем слабее выражена асимметрия распределения. Таким образом, распределение количества неправильно заполненных форм смещено вправо, поскольку p = 0,1 (рис. 4).

Рис. 4. Гистограмма биномиального распределения при n = 4 и p = 0,1
Математическое ожидание биномиального распределения равно произведению объема выборки n на вероятность успеха р :
(3) Μ = Е(Х) = np
В среднем, при достаточно долгой серии испытаний в выборке, состоящей из четырех заказов, может оказаться р = Е(Х) = 4 х 0,1 = 0,4 неправильно заполненных форм.
Стандартное отклонение биномиального распределения
Например, стандартное отклонение количества неверно заполненных форм в бухгалтерской информационной системе равно:
Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 307–313
Рассмотрим Биномиальное распределение, вычислим его математическое ожидание, дисперсию, моду. С помощью функции MS EXCEL БИНОМ.РАСП() построим графики функции распределения и плотности вероятности. Произведем оценку параметра распределения p, математического ожидания распределения и стандартного отклонения. Также рассмотрим распределение Бернулли.
Определение . Пусть проводятся n испытаний, в каждом из которых может произойти только 2 события: событие «успех» с вероятностью p или событие «неудача» с вероятностью q =1-p (так называемая Схема Бернулли, Bernoulli trials ).
Вероятность получения ровно x успехов в этих n испытаниях равна:
Количество успехов в выборке x является случайной величиной, которая имеет Биномиальное распределение (англ. Binomial distribution ) p и n – являются параметрами этого распределения.
Напомним, что для применения схемы Бернулли и соответственно Биномиального распределения, должны быть выполнены следующие условия:
- каждое испытание должно иметь ровно два исхода, условно называемых «успехом» и «неудачей».
- результат каждого испытания не должен зависеть от результатов предыдущих испытаний (независимость испытаний).
- вероятность успеха p должна быть постоянной для всех испытаний.
Биномиальное распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Биномиального распределения имеется функция БИНОМ.РАСП() , английское название - BINOM.DIST(), которая позволяет вычислить вероятность того, что в выборке будет ровно х «успехов» (т.е. функцию плотности вероятности p(x), см. формулу выше), и интегральную функцию распределения (вероятность того, что в выборке будет x или меньше «успехов», включая 0).
До MS EXCEL 2010 в EXCEL была функция БИНОМРАСП() , которая также позволяет вычислить функцию распределения и плотность вероятности p(x). БИНОМРАСП() оставлена в MS EXCEL 2010 для совместимости.
В файле примера приведены графики плотности распределения вероятности и .

Биномиальное распределения имеет обозначение B (n ; p ) .
Примечание : Для построения интегральной функции распределения идеально подходит диаграмма типа График , для плотности распределения – Гистограмма с группировкой . Подробнее о построении диаграмм читайте статью Основные типы диаграмм.
Примечание : Для удобства написания формул в файле примера созданы Имена для параметров Биномиального распределения : n и p.

В файле примера приведены различные расчеты вероятности с помощью функций MS EXCEL:

Как видно на картинке выше, предполагается, что:
- В бесконечной совокупности, из которой делается выборка, содержится 10% (или 0,1) годных элементов (параметр p , третий аргумент функции =БИНОМ.РАСП() )
- Чтобы вычислить вероятность, того что в выборке из 10 элементов (параметр n , второй аргумент функции) будет ровно 5 годных элементов (первый аргумент), нужно записать формулу: =БИНОМ.РАСП(5; 10; 0,1; ЛОЖЬ)
- Последний, четвертый элемент, установлен =ЛОЖЬ, т.е. возвращается значение функции плотности распределения .
Если значение четвертого аргумента =ИСТИНА, то функция БИНОМ.РАСП() возвращает значение интегральной функции распределения или просто Функцию распределения . В этом случае можно рассчитать вероятность того, что в выборке количество годных элементов будет из определенного диапазона, например, 2 или меньше (включая 0).
Для этого нужно записать формулу:
= БИНОМ.РАСП(2; 10; 0,1; ИСТИНА)
Примечание
: При нецелом значении х, . Например, следующие формулы вернут одно и тоже значение:
=БИНОМ.РАСП(2
; 10; 0,1; ИСТИНА)
=БИНОМ.РАСП(2,9
; 10; 0,1; ИСТИНА)
Примечание : В файле примера плотность вероятности и функция распределения также вычислены с использованием определения и функции ЧИСЛКОМБ() .
Показатели распределения
В файле примера на листе Пример имеются формулы для расчета некоторых показателей распределения:
- =n*p;
- (квадрата стандартного отклонения) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*КОРЕНЬ(n*p*(1-p)).
Выведем формулу математического ожидания Биномиального распределения , используя Схему Бернулли .
По определению случайная величина Х в схеме Бернулли (Bernoulli random variable) имеет функцию распределения :
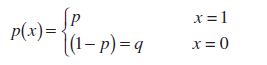
Это распределение называется распределение Бернулли .
Примечание : распределение Бернулли – частный случай Биномиального распределения с параметром n=1.
Сгенерируем 3 массива по 100 чисел с различными вероятностями успеха: 0,1; 0,5 и 0,9. Для этого в окне Генерация случайных чисел установим следующие параметры для каждой вероятности p:

Примечание : Если установить опцию Случайное рассеивание (Random Seed ), то можно выбрать определенный случайный набор сгенерированных чисел. Например, установив эту опцию =25 можно сгенерировать на разных компьютерах одни и те же наборы случайных чисел (если, конечно, другие параметры распределения совпадают). Значение опции может принимать целые значения от 1 до 32 767. Название опции Случайное рассеивание может запутать. Лучше было бы ее перевести как Номер набора со случайными числами .
В итоге будем иметь 3 столбца по 100 чисел, на основании которых можно, например, оценить вероятность успеха p по формуле: Число успехов/100 (см. файл примера лист ГенерацияБернулли ).

Примечание : Для распределения Бернулли с p=0,5 можно использовать формулу =СЛУЧМЕЖДУ(0;1) , которая соответствует .
Генерация случайных чисел. Биномиальное распределение
Предположим, что в выборке обнаружилось 7 дефектных изделий. Это означает, что «очень вероятна» ситуация, что изменилась доля дефектных изделий p , которая является характеристикой нашего производственного процесса. Хотя такая ситуация «очень вероятна», но существует вероятность (альфа-риск, ошибка 1-го рода, «ложная тревога»), что все же p осталась без изменений, а увеличенное количество дефектных изделий обусловлено случайностью выборки.
Как видно на рисунке ниже, 7 – количество дефектных изделий, которое допустимо для процесса с p=0,21 при том же значении Альфа . Это служит иллюстрацией, что при превышении порогового значения дефектных изделий в выборке, p «скорее всего» увеличилось. Фраза «скорее всего» означает, что существует всего лишь 10% вероятность (100%-90%) того, что отклонение доли дефектных изделий выше порогового вызвано только сучайными причинами.
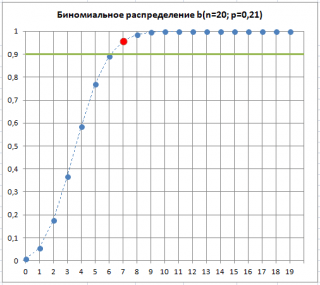
Таким образом, превышение порогового количества дефектных изделий в выборке, может служить сигналом, что процесс расстроился и стал выпускать бо льший процент бракованных изделий.
Примечание : До MS EXCEL 2010 в EXCEL была функция КРИТБИНОМ() , которая эквивалентна БИНОМ.ОБР() . КРИТБИНОМ() оставлена в MS EXCEL 2010 и выше для совместимости.
Связь Биномиального распределения с другими распределениями
Если параметр n
Биномиального распределения
стремится к бесконечности, а p
стремится к 0, то в этом случае Биномиальное распределение
может быть аппроксимировано .
Можно сформулировать условия, когда приближение распределением Пуассона
работает хорошо:
- p <0,1 (чем меньше p и больше n , тем приближение точнее);
- p >0,9 (учитывая, что q =1- p , вычисления в этом случае необходимо производить через q (а х нужно заменить на n - x ). Следовательно, чем меньше q и больше n , тем приближение точнее).
При 0,1<=p<=0,9 и n*p>10 Биномиальное распределение можно аппроксимировать .
В свою очередь, Биномиальное распределение может служить хорошим приближением , когда размер совокупности N Гипергеометрического распределения гораздо больше размера выборки n (т.е., N>>n или n/N<<1).
Подробнее о связи вышеуказанных распределений, можно прочитать в статье . Там же приведены примеры аппроксимации, и пояснены условия, когда она возможна и с какой точностью.
СОВЕТ : О других распределениях MS EXCEL можно прочитать в статье .
Распределения вероятностей дискретных случайных величин. Биномиальное распределение. Распределение Пуассона. Геометрическое распределение. Производящая функция.
6. Распределения вероятностей дискретных случайных величин
6.1. Биномиальное распределение
Пусть производится n независимых испытаний, в каждом из которых событие A может либо появится, либо не появится. Вероятность p появления события A во всех испытаниях постоянна и не изменяется от испытания к испытанию. Рассмотрим в качестве случайной величины X число появлений события A в этих испытаниях. Формула, позволяющая найти вероятность появления события A ровно k раз в n испытаниях, как известно, описывается формулой Бернулли
Распределение вероятностей, определяемое формулой Бернулли, называется биномиальным .
Этот закон назван "биномиальным" потому, что правую часть можно рассматривать как общий член разложения бинома Ньютона
Запишем биномиальный закон в виде таблицы
|
p n |
np n –1 q |
|
q n |

Найдем числовые характеристики этого распределения.
По определению математического ожидания для ДСВ имеем
 .
.
Запишем равенство, являющееся бином Ньютона
 .
.
и продифференцируем его по p. В результате получим
 .
.
Умножим левую и правую часть на p :
 .
.
Учитывая, что p + q =1, имеем
 (6.2)
(6.2)
Итак, математическое ожидание числа появлений событий в n независимых испытаниях равно произведению числа испытаний n на вероятность p появления события в каждом испытании .
Дисперсию вычислим по формуле
 .
.
Для этого найдем
 .
.
Предварительно продифференцируем формулу бинома Ньютона два раза по p :

и умножим обе части равенства на p 2:

Следовательно,
Итак, дисперсия биномиального распределения равна
 .
(6.3)
.
(6.3)
Данные результаты можно получить и из чисто качественных рассуждений. Общее число X появлений события A во всех испытаниях складываются из числа появлений события в отдельных испытаниях. Поэтому если X 1 – число появлений события в первом испытании, X 2 – во втором и т.д., то общее число появлений события A во всех испытаниях равно X=X 1 +X 2 +…+X n . По свойству математического ожидания:
Каждое из слагаемых правой части равенства есть математическое ожидание числа событий в одном испытании, которое равно вероятности события. Таким образом,
По свойству дисперсии:
Так
как
,
а математическое ожидание случайной
величины ,
которое может принимать только два
значения, а именно 1 2
с вероятностью p
и 0 2
с вероятностью q
,
то
,
которое может принимать только два
значения, а именно 1 2
с вероятностью p
и 0 2
с вероятностью q
,
то
 .
Таким образом,
.
Таким образом, В результате, получаем
В результате, получаем
Воспользовавшись понятием начальных и центральных моментов, можно получить формулы для асимметрии и эксцесса:
 .
(6.4)
.
(6.4)

Рис. 6.1
Многоугольник биномиального распределения имеет следующий вид (см. рис. 6.1). ВероятностьP n (k ) сначала возрастает при увеличении k , достигает наибольшего значения и далее начинает убывать. Биномиальное распределение асимметрично, за исключением случая p =0,5. Отметим, что при большом числе испытаний n биномиальное распределение весьма близко к нормальному. (Обоснование этого предложения связано с локальной теоремой Муавра-Лапласа.)Число m 0 наступлений события называется наивероятнейшим , если вероятность наступления события данное число раз в этой серии испытаний наибольшая (максимум в многоугольнике распределения) . Для биномиального распределения
Замечание. Данное неравенство можно доказать, используя рекуррентную формулу для биномиальных вероятностей:
 (6.6)
(6.6)
Пример 6.1. Доля изделий высшего сорта на данном предприятии составляет 31%. Чему равно математического ожидание и дисперсия, также наивероятнейшее число изделий высшего сорта в случайно отобранной партии из 75 изделий?
Решение. Поскольку p =0,31, q =0,69, n =75, то
M[X ] = np = 750,31 = 23,25; D[X ] = npq = 750,310,69 = 16,04.
Для нахождения наивероятнейшего числа m 0 , составим двойное неравенство
Отсюда следует, что m 0 = 23.
Биномиальное распределение
распределение вероятностей числа появлений некоторого события при повторных независимых испытаниях. Если при каждом испытании вероятность появления события равна р,
причём 0 ≤ p
≤ 1, то число μ появлений этого события при n
независимых испытаниях есть случайная величина, принимающая значения m
= 1, 2,.., n
с вероятностями где q
= 1 - p,
a Лит.:
Большев Л. Н., Смирнов Н. В., Таблицы математической статистики, М., 1965.![]() -
биномиальные коэффициенты (отсюда название Б. р.). Приведённая формула иногда называется формулой Бернулли. Математическое ожидание и Дисперсия величины μ, имеющей Б. р., равны М
(μ) = np
и D
(μ) = npq
, соответственно. При больших n,
в силу Лапласа теоремы (См. Лапласа теорема), Б. р. близко к нормальному распределению (См. Нормальное распределение), чем и пользуются на практике. При небольших n
приходится пользоваться таблицами Б. р.
-
биномиальные коэффициенты (отсюда название Б. р.). Приведённая формула иногда называется формулой Бернулли. Математическое ожидание и Дисперсия величины μ, имеющей Б. р., равны М
(μ) = np
и D
(μ) = npq
, соответственно. При больших n,
в силу Лапласа теоремы (См. Лапласа теорема), Б. р. близко к нормальному распределению (См. Нормальное распределение), чем и пользуются на практике. При небольших n
приходится пользоваться таблицами Б. р.
Большая советская энциклопедия. - М.: Советская энциклопедия . 1969-1978 .
Смотреть что такое "Биномиальное распределение" в других словарях:
Функция вероятности … Википедия
- (binomial distribution) Распределение, позволяющее рассчитать вероятность наступления какого либо случайного события, полученного в результате наблюдений ряда независимых событий, если вероятность наступления, составляющих его элементарных… … Экономический словарь
- (распределение Бернулли) распределение вероятностей числа появлений некоторого события при повторных независимых испытаниях, если вероятность появления этого события в каждом испытании равна p(0 p 1). Именно, число? появлений этого события есть… … Большой Энциклопедический словарь
биномиальное распределение - — Тематики электросвязь, основные понятия EN binomial distribution …
- (распределение Бернулли), распределение вероятностей числа появлений некоторого события при повторных независимых испытаниях, если вероятность появления этого события в каждом испытании равна р (0≤р≤1). Именно, число μ появлений этого события… … Энциклопедический словарь
биномиальное распределение - 1.49. биномиальное распределение Распределение вероятностей дискретной случайной величины X, принимающей любые целые значения от 0 до n, такое что при х = 0, 1, 2, ..., n и параметрах n = 1, 2, ... и 0 < p < 1, где Источник … Словарь-справочник терминов нормативно-технической документации
Распределение Бернулли, распределение вероятностей случайной величины X, принимающей целочисленные значения с вероятностями соответственно (биномиальный коэффициент; р параметр Б. р., наз. вероятностью положительного исхода, принимающей значения … Математическая энциклопедия
- (распределение Бернулли), распределение вероятностей числа появлений нек рого события при повторных независимых испытаниях, если вероятность появления этого события в каждом испытании равна р (0<или = p < или = 1). Именно, число м появлений … Естествознание. Энциклопедический словарь
Биномиальное распределение вероятностей - (binomial distribution) Распределение, которое наблюдается в случаях, когда исход каждого независимого эксперимента (статистического наблюдения) принимает одно из двух возможных значений: победа или поражение, включение или исключение, плюс или … Экономико-математический словарь
биномиальное распределение вероятностей - Распределение, которое наблюдается в случаях, когда исход каждого независимого эксперимента (статистического наблюдения) принимает одно из двух возможных значений: победа или поражение, включение или исключение, плюс или минус, 0 или 1. То есть… … Справочник технического переводчика
Книги
- Теория вероятностей и математическая статистика в задачах. Более 360 задач и упражнений , Д. А. Борзых. В предлагаемом пособии содержатся задачи различного уровня сложности. Однако основной акцент сделан на задачах средней сложности. Это сделано намеренно с тем, чтобы побудить студентов к…
- Теория вероятностей и математическая статистика в задачах: Более 360 задач и упражнений , Борзых Д.. В предлагаемом пособии содержатся задачи различного уровня сложности. Однако основной акцент сделан на задачах средней сложности. Это сделано намеренно с тем, чтобы побудить студентов к…