|
Z 1 (t) |
Z 2 (t) |
t |
y(t) |
|
|
Z 1 (t) | ||||
|
Z 2 (t) | ||||
|
t | ||||
|
y(t) |
Основная задача, стоящая при выборе факторов включаемых в корреляционную модель, заключается в том, чтобы ввести в анализ все основные факторы, влияющие на уровень изучаемого явления. Однако, введение в модель большого числа факторов нецелесообразно, правильнее отобрать только сравнительно небольшое число основных факторов, находящихся предположительно в корреляционной зависимости с выбранным функциональным показателем.
Это можно сделать с помощью так называемого двух стадийного отбора. В соответствии с ним в модель включаются все предварительно отобранные факторы. Затем среди них на основе специальной количественной оценки и дополнительно качественного анализа выявляются несущественно влияющие факторы, которые постепенно отбрасываются пока не останутся те, относительно которых можно утверждать, что имеющийся статистический материал согласуется с гипотезой об их совместном существенном влиянии на зависимую переменную при выбранной форме связи.
Свое наиболее законченное выражение двух стадийный отбор получил в методике так называемого многошагового регрессионного анализа, при котором отсев несущественных факторов происходит на основе показателей их значимости, в частности на основе величины t ф - расчетном значении критерия Стьюдента.
Рассчитаем t ф по найденным коэффициентам парной корреляции и сравним их с t критическим для 5% уровня значимости (двустороннего) и 18 степенями свободы (ν = n-2).
где r – значение коэффициента парной корреляции;
n – число наблюдений (n=20)
При сравнении t ф для каждого коэффициента с t кр = 2,101 получаем, что найденные коэффициенты признаются значимыми, т.к. t ф > t кр.
t ф для r yx 1 = 2, 5599 ;
t ф для r yx 2 = 7,064206 ;
t ф для r yx 3 = 2,40218 ;
t ф для r х1 x 2 = 4,338906 ;
t ф для r х1 x 3 = 15,35065;
t ф для r х2 x 3 = 4,749981
При отборе факторов включаемых в анализ к ним предъявляются специфические требования. Прежде всего, показатели, выражающие эти факторы должны быть количественно измеримы.
Факторы, включаемые в модель, не должны находиться между собой в функциональной или близкой к ней связи. Наличие таких связей характеризуется мультиколлинеарностью.
Мультиколлинеарность свидетельствует о том, что некоторые факторы характеризуют одну и ту же сторону изучаемого явления. Поэтому их одновременное включение в модель нецелесообразно, так как они в определённой степени дублируют друг друга. Если нет особых предположений говорящих в пользу одного из этих факторов, следует отдавать предпочтение тому из них, который характеризуется большим коэффициентом парной (или частной) корреляции.
Считается, что предельным является значение коэффициента корреляции между двумя факторами, равное 0,8.
Мультиколлинеарность обычно приводит к вырождению матрицы переменных и, следовательно, к тому, что главный определитель уменьшает свое значение и в пределе становится близок к нулю. Оценки коэффициентов уравнения регрессии становятся сильно зависимыми от точности нахождения исходных данных и резко изменяют свои значения при изменении количества наблюдений.
1. ПОСТРОИМ МАТРИЦУ КОЭФФИЦИЕНТОВ ПАРНОЙ КОРРЕЛЯЦИИ.
Для этого рассчитаем коэффициенты парной корреляции по формуле:
Необходимые расчеты представлены в таблице 9.
![]() -
-
связь между выручкой предприятия Y и объемом капиталовложений Х 1 слабая и прямая;
![]() -
-
связи между выручкой предприятия Y и основными производственными фондами Х 2 практически нет;
![]() -
-
связь между объемом капиталовложений Х 1 и основными производственными фондами Х 2 тесная и прямая;
Таблица 9
Вспомогательная таблица для расчета коэффициентов парных корреляций
| t | Y | X1 | X2 | (y-yср)* | (y-yср)* | (х1-х1ср)* |
|||
| 1998 | 3,0 | 1,1 | 0,4 | 0,0196 | 0,0484 | 0,0841 | 0,0308 | 0,0406 | 0,0638 |
| 1999 | 2,9 | 1,1 | 0,4 | 0,0576 | 0,0484 | 0,0841 | 0,0528 | 0,0696 | 0,0638 |
| 2000 | 3,0 | 1,2 | 0,7 | 0,0196 | 0,0144 | 1E-04 | 0,0168 | -0,0014 | -0,0012 |
| 2001 | 3,1 | 1,4 | 0,9 | 0,0016 | 0,0064 | 0,0441 | -0,0032 | -0,0084 | 0,0168 |
| 2002 | 3,2 | 1,4 | 0,9 | 0,0036 | 0,0064 | 0,0441 | 0,0048 | 0,0126 | 0,0168 |
| 2003 | 2,8 | 1,4 | 0,8 | 0,1156 | 0,0064 | 0,0121 | -0,0272 | -0,0374 | 0,0088 |
| 2004 | 2,9 | 1,3 | 0,8 | 0,0576 | 0,0004 | 0,0121 | 0,0048 | -0,0264 | -0,0022 |
| 2005 | 3,4 | 1,6 | 1,1 | 0,0676 | 0,0784 | 0,1681 | 0,0728 | 0,1066 | 0,1148 |
| 2006 | 3,5 | 1,3 | 0,4 | 0,1296 | 0,0004 | 0,0841 | -0,0072 | -0,1044 | 0,0058 |
| 2007 | 3,6 | 1,4 | 0,5 | 0,2116 | 0,0064 | 0,0361 | 0,0368 | -0,0874 | -0,0152 |
| Σ | 31,4 | 13,2 | 6,9 | 0,684 | 0,216 | 0,569 | 0,182 | -0,036 | 0,272 |
| Средн. | 3,14 | 1,32 | 0,69 |
Также матрицу коэффициентов парных корреляций можно найти в среде Excel с помощью надстройки АНАЛИЗ ДАННЫХ, инструмента КОРРЕЛЯЦИЯ.
Матрица коэффициентов парной корреляции имеет вид:
| Y | X1 | X2 | |
| Y | 1 | ||
| X1 | 0,4735 | 1 | |
| X2 | -0,0577 | 0,7759 | 1 |
Матрица парных коэффициентов корреляции показывает, что результативный признак у (выручка) имеет слабую связь с объемом капиталовложений х 1 , а с Размером ОПФ связи практически нет. Связь между факторами в модели оценивается как тесная, что говорит о их линейной зависимости, мультиколлинеарности.
2. ПОСТРОИТЬ ЛИНЕЙНУЮ МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ ![]()
Параметры модели найдем с помощью МНК. Для этого составим систему нормальных уравнений.

Расчеты представлены в таблице 10.

Решим систему уравнений, используя метод Крамера:




![]()
![]()
![]()
Таблица 10
Вспомогательные вычисления для нахождения параметров линейной модели множественной регрессии
| y | |||||||
| 3,0 | 1,1 | 0,4 | 1,21 | 0,44 | 0,16 | 3,3 | 1,2 |
| 2,9 | 1,1 | 0,4 | 1,21 | 0,44 | 0,16 | 3,19 | 1,16 |
| 3,0 | 1,2 | 0,7 | 1,44 | 0,84 | 0,49 | 3,6 | 2,1 |
| 3,1 | 1,4 | 0,9 | 1,96 | 1,26 | 0,81 | 4,34 | 2,79 |
| 3,2 | 1,4 | 0,9 | 1,96 | 1,26 | 0,81 | 4,48 | 2,88 |
| 2,8 | 1,4 | 0,8 | 1,96 | 1,12 | 0,64 | 3,92 | 2,24 |
| 2,9 | 1,3 | 0,8 | 1,69 | 1,04 | 0,64 | 3,77 | 2,32 |
| 3,4 | 1,6 | 1,1 | 2,56 | 1,76 | 1,21 | 5,44 | 3,74 |
| 3,5 | 1,3 | 0,4 | 1,69 | 0,52 | 0,16 | 4,55 | 1,4 |
| 3,6 | 1,4 | 0,5 | 1,96 | 0,7 | 0,25 | 5,04 | 1,8 |
| 31,4 | 13,2 | 6,9 | 17,64 | 9,38 | 5,33 | 41,63 | 21,63 |
Линейная модель множественной регрессии имеет вид:
Если объем капиталовложений увеличить на 1 млн. руб., то выручка предприятия увеличиться в среднем на 2,317 млн. руб. при неизменных размерах основных производственных фондов.
Если основные производственные фонды увеличить на 1 млн. руб., то выручка предприятия уменьшиться в среднем на 1,171 млн. руб. при неизменном объеме капиталовложений.
3. РАССЧИТАЕМ:
коэффициент детерминации:
67,82% изменения выручки предприятия обусловлено изменением объема капиталовложений и основных производственных фондов, на 32,18% - влиянием факторов, не включенных в модель.
F – критерий Фишера
Проверим значимость уравнения
Табличное значение F – критерия при уровне значимости α = 0,05 и числе степеней свободы d.f. 1 = k = 2 (количество факторов), числе степеней свободы d.f. 2 = (n – k – 1) = (10 – 2 – 1) = 7 составит 4,74.
Так как F расч. = 7,375 > F табл. = 4.74, то уравнение регрессии в целом можно считать статистически значимым.
Рассчитанные показатели можно найти в среде Excel с помощью надстройки АНАЛИЗА ДАННЫХ, инструмента РЕГРЕССИЯ.
Таблица 11
Вспомогательные вычисления для нахождения средней относительной ошибки аппроксимации
| y | А | ||||
| 3,0 | 1,1 | 0,4 | 2,97 | 0,03 | 0,010 |
| 2,9 | 1,1 | 0,4 | 2,97 | -0,07 | 0,024 |
| 3,0 | 1,2 | 0,7 | 2,85 | 0,15 | 0,050 |
| 3,1 | 1,4 | 0,9 | 3,08 | 0,02 | 0,007 |
| 3,2 | 1,4 | 0,9 | 3,08 | 0,12 | 0,038 |
| 2,8 | 1,4 | 0,8 | 3,20 | -0,40 | 0,142 |
| 2,9 | 1,3 | 0,8 | 2,96 | -0,06 | 0,022 |
| 3,4 | 1,6 | 1,1 | 3,31 | 0,09 | 0,027 |
| 3,5 | 1,3 | 0,4 | 3,43 | 0,07 | 0,019 |
| 3,6 | 1,4 | 0,5 | 3,55 | 0,05 | 0,014 |
| 0,353 |
среднюю относительную ошибку аппроксимации
В среднем расчетные значения отличаются от фактических на 3,53 %. Ошибка небольшая, модель можно считать точной.
4. Построить степенную модель множественной регрессии ![]()
Для построения данной модели прологарифмируем обе части равенства
lg y = lg a + β 1 ∙ lg x 1 + β 2 ∙ lg x 2 .
Сделаем замену Y = lg y, A = lg a, X 1 = lg x 1 , X 2 = lg x 2 .
Тогда Y = A + β 1 ∙ X 1 + β 2 ∙ X 2 – линейная двухфакторная модель регрессии. Можно применить МНК.

Расчеты представлены в таблице 12.

Таблица 12
Вспомогательные вычисления для нахождения параметров степенной модели множественной регрессии
| y | lg y | |||||||||
| 3,0 | 1,1 | 0,4 | 0,041 | -0,398 | 0,477 | 0,002 | -0,016 | 0,020 | 0,158 | -0,190 |
| 2,9 | 1,1 | 0,4 | 0,041 | -0,398 | 0,462 | 0,002 | -0,016 | 0,019 | 0,158 | -0,184 |
| 3,0 | 1,2 | 0,7 | 0,079 | -0,155 | 0,477 | 0,006 | -0,012 | 0,038 | 0,024 | -0,074 |
| 3,1 | 1,4 | 0,9 | 0,146 | -0,046 | 0,491 | 0,021 | -0,007 | 0,072 | 0,002 | -0,022 |
| 3,2 | 1,4 | 0,9 | 0,146 | -0,046 | 0,505 | 0,021 | -0,007 | 0,074 | 0,002 | -0,023 |
| 2,8 | 1,4 | 0,8 | 0,146 | -0,097 | 0,447 | 0,021 | -0,014 | 0,065 | 0,009 | -0,043 |
| 2,9 | 1,3 | 0,8 | 0,114 | -0,097 | 0,462 | 0,013 | -0,011 | 0,053 | 0,009 | -0,045 |
| 3,4 | 1,6 | 1,1 | 0,204 | 0,041 | 0,531 | 0,042 | 0,008 | 0,108 | 0,002 | 0,022 |
| 3,5 | 1,3 | 0,4 | 0,114 | -0,398 | 0,544 | 0,013 | -0,045 | 0,062 | 0,158 | -0,217 |
| 3,6 | 1,4 | 0,5 | 0,146 | -0,301 | 0,556 | 0,021 | -0,044 | 0,081 | 0,091 | -0,167 |
| 31,4 | 13,2 | 6,9 | 1,178 | -1,894 | 4,955 | 0,163 | -0,165 | 0,592 | 0,614 | -0,943 |
Решаем систему уравнений применяя метод Крамера.




![]()
![]()
Степенная модель множественной регрессии имеет вид:
![]()
В степенной функции коэффициенты при факторах являются коэффициентами эластичности. Коэффициент эластичности показывает на сколько процентов измениться в среднем значение результативного признака у, если один из факторов увеличить на 1 % при неизменном значении других факторов.
Если объем капиталовложений увеличить на 1%, то выручка предприятия увеличиться в среднем на 0,897% при неизменных размерах основных производственных фондов.
Если основные производственные фонды увеличить на 1%, то выручка предприятия уменьшиться на 0,226% при неизменных капиталовложениях.
5. РАССЧИТАЕМ:
коэффициент множественной корреляции:

Связь выручки предприятия с объемом капиталовложений и основными производственными фондами тесная.
Таблица 13
Вспомогательные вычисления для нахождения коэффициента множественной корреляции, коэффициента детерминации, ср.относ.ошибки аппроксимации степенной модели множественной регрессии
| Y | (Y-Y расч.) 2 | A | ||||
| 3,0 | 1,1 | 0,4 | 2,978 | 0,000 | 0,020 | 0,007 |
| 2,9 | 1,1 | 0,4 | 2,978 | 0,006 | 0,058 | 0,027 |
| 3,0 | 1,2 | 0,7 | 2,838 | 0,026 | 0,020 | 0,054 |
| 3,1 | 1,4 | 0,9 | 3,079 | 0,000 | 0,002 | 0,007 |
| 3,2 | 1,4 | 0,9 | 3,079 | 0,015 | 0,004 | 0,038 |
| 2,8 | 1,4 | 0,8 | 3,162 | 0,131 | 0,116 | 0,129 |
| 2,9 | 1,3 | 0,8 | 2,959 | 0,003 | 0,058 | 0,020 |
| 3,4 | 1,6 | 1,1 | 3,317 | 0,007 | 0,068 | 0,024 |
| 3,5 | 1,3 | 0,4 | 3,460 | 0,002 | 0,130 | 0,012 |
| 3,6 | 1,4 | 0,5 | 3,516 | 0,007 | 0,212 | 0,023 |
| 31,4 | 13,2 | 6,9 | 0,198 | 0,684 | 0,342 |
коэффициент детерминации:
71,06% изменения выручки предприятия в степенной модели обусловлено изменением объема капиталовложений и основных производственных фондов, на 28,94 % - влиянием факторов, не включенных в модель.
F – критерий Фишера
Проверим значимость уравнения
Табличное значение F – критерия при уровне значимости α = 0,05 и числе степеней свободы d.f. 1 = k = 2, числе степеней свободы d.f. 2 = (n – k – 1) = (10 – 2 – 1) = 7 составит 4,74.
Так как F расч. = 8,592 > F табл. = 4.74, то уравнение степенной регрессии в целом можно считать статистически значимым.
Посадка невозможна, в каком из реализуемых случаев расход топлива меньше. Получить программу оптимального управления, когда до некоторого момента t1 управление отсутствует u*=0, а начиная с t=t1, управление равно своему максимальному значению u*=umax, что соответствует минимальному расходу топлива. 6.) Решить каноническую систему уравнений, рассматривая ее для случаев, когда и управление...
К составлению математических моделей. Если математическая модель - это диагноз заболевания, то алгоритм - это метод лечения. Можно выделить следующие основные этапы операционного исследования: наблюдение явления и сбор исходных данных; постановка задачи; построение математической модели; расчет модели; тестирование модели и анализ выходных данных. Если полученные результаты не удовлетворяют...
Математических построений по аналогии с выявляет в плоском приближении продольно-скалярную электромагнитную волну с электрической - (28) и магнитной (29) синфазными составляющими. Математическая модель безвихревой электродинамики характеризуется скалярно-векторной структурой своих уравнений. Основополагающие уравнения безвихревой электродинамики сведены в таблице 1. Таблица 1 , ...
По территориям Южного федерального округа РФ приводятся данные за 2011 год
|
Территории федерального округа |
Валовой региональный продукт, млрд. руб., Y |
Инвестиции в основной капитал, млрд. руб., X1 |
|
1. Респ. Адыгея |
||
|
2. Респ. Дагестан |
||
|
3. Респ. Ингушетия |
||
|
4. Кабардино-БалкарскаяРесп. |
||
|
5. Респ. Калмыкия |
||
|
6. Карачаево-ЧеркесскаяРесп. |
||
|
7. Респ. Северная Осетия - Алания |
||
|
8. Краснодарский кра) |
||
|
9. Ставропольский край |
||
|
10. Астраханская обл. |
||
|
11. Волгоградская обл. |
||
|
12. Ростовская обл. |
- 1. Рассчитайте матрицу парных коэффициентов корреляции; оцените статистическую значимость коэффициентов корреляции.
- 2. Постройте поле корреляции результативного признака и наиболее тесно связанного с ним фактора.
- 3. Рассчитайте параметры линейной парной регрессии для каждого фактора Х..
- 4. Оцените качество каждой модели через коэффициент детерминации, среднюю ошибку аппроксимации и F-критерий Фишера. Выберите лучшую модель.
составит 80% от его максимального значения. Представьте графически: фактические и модельные значения, точки прогноза.
- 6. Используя пошаговую множественную регрессию (метод исключения или метод включения), постройте модель формирования цены квартиры за счёт значимых факторов. Дайте экономическую интерпретацию коэффициентов модели регрессии.
- 7. Оцените качество построенной модели. Улучшилось ли качество модели по сравнению с однофакторной моделью? Дайте оценку влияния значимых факторов на результат с помощью коэффициентов эластичности,в - и -? коэффициентов.
При решении данной задачи расчеты и построение графиков и диаграмм будем вести с использованием настройки Excel Анализ данных.
1. Рассчитаем матрицу парных коэффициентов корреляции и оценим статистическую значимость коэффициентов корреляции
В диалоговом окне Корреляция в поле Входной интервал вводим диапазон ячеек, содержащих исходные данные. Так как мы выделили и заголовки столбцов, то устанавливаем флажок Метки в первой строке.
Получили следующие результаты:
Таблица 1.1 Матрица парных коэффициентов корреляции
Анализ матрицы коэффициентов парной корреляции показывает, что зависимая переменная Y, т.е валового регионального продукта имеет более тесную связь с Х1 (инвестиции в основной капитал). Коэффициент корреляции равен 0,936. Это означает, что на 93,6% зависимая переменная Y (валовой региональный продукт) зависит от показателя Х1 (инвестиции в основной капитал).
Статистическая значимость коэффициентов корреляции определим с помощью t-критерия Стьюдента. Табличное значение сравниваем с расчетными значениями.
Вычислим табличное значение с помощью функции СТЬЮДРАСПОБР.
t табл.=0,129 при доверительной вероятности равной 0,9 и степенью свободы (n-2).
Статистическим значимым является фактор Х1.
2. Построим поле корреляции результативного признака (валового регионального продукта) и наиболее тесно связанного с ним фактора (инвестиции в основной капитал)
Для этого воспользуемся инструментом построения точечной диаграммы программы Excel.
В результате получаем поле корреляции цены валового регионального продукта, млрд. руб. и инвестиции в основной капитал, млрд. руб. (рисунок 1.1.).
Рисунок 1.1
3. Рассчитаем параметры линейной парной регрессии для каждого фактора Х
Для расчета параметров линейной парной регрессии воспользуемся инструментом Регрессия, входящим в настойку Анализ данных.
В диалоговом окне Регрессия в поле Входной интервал Y вводим адрес диапазона ячеек, которые представляет зависимую переменную. В поле
Входной интервал Х вводим адрес диапазона, который содержит значения независимых переменных. Выполним вычисления параметры парной регрессии для фактора Х.
Для Х1 получили следующие данные, представленные в таблице 1.2:
Таблица 1.2
Уравнение регрессии зависимости цены валового регионального продукта от инвестиции в основной капитал имеет вид:
4. Оценим качество каждой модели через коэффициент детерминации, среднюю ошибку аппроксимации и F-критерий Фишера. Установим, какая модель является лучшей.
Коэффициент детерминации, среднюю ошибку аппроксимации мы получили в результате расчетов, проведенных в пункте 3. Полученные данные представлены в следующих таблицах:
Данные по Х1:
Таблица 1.3а
Таблица 1.4б
А) Коэффициент детерминации определяет, какая доля вариации признака У учтена в модели и обусловлена влиянием на него фактора Х. Чем больше значение коэффициента детерминации, тем теснее связь между признаками в построенной математической модели.
В программе Excel обозначается R-квадрат.
Исходя из данного критерия наиболее адекватной является модель уравнения регрессии зависимости цены валового регионального продукта от инвестиции в основной капитал (Х1).
Б) Среднюю ошибку аппроксимации рассчитаем по формуле:
где числитель - сумма квадратов отклонения расчетных значений от фактических. В таблицах она находится в столбце SS, строке Остатки.
Среднее значение цены квартиры рассчитаем в Excel с помощью функции СРЗНАЧ. = 24,18182 млрд. руб.
При проведении экономических расчетов модель считается достаточно точной, если средняя ошибка аппроксимации меньше 5%, модель считается приемлемой, если средняя ошибка аппроксимации меньше 15%.
По данному критерию, наиболее адекватной является математическая модель для уравнения регрессии зависимости цены валового регионального продукта от инвестиции в основной капитал (Х1).
В) Для проверки значимости модели регрессии используется F-тест. Для этого выполняется сравнение и критического (табличного)значений F-критерия Фишера.
Расчетные значения приведены в таблицах 1.4б (обозначены буквой F).
Табличное значение F-критерий Фишера рассчитаем в Excel с помощью функции FРАСПОБР. Вероятность возьмем равной 0,05. Получили: = 4,75
Расчетные значения F-критерий Фишера для каждого фактора сравним с табличным значением:
71,02 > = 4,75 модель по данному критерию адекватна.
Проанализировав данные по всем трем критериям, можно сделать вывод, что наиболее лучшей является математическая модель, построена для фактора валового регионального продукта, которая описана линейным уравнением
5. Для выбранной модели зависимости цены валового регионального продукта
осуществим прогнозирование среднего значения показателя при уровне значимости, если прогнозное значения фактора составит 80% от его максимального значения. Представим графически: фактические и модельные значения, точки прогноза.
Рассчитаем прогнозное значение Х, по условию оно составит 80% от максимального значения.
Рассчитаем Х max в Excel с помощью функции МАКС.
0,8 *52,8 = 42,24
Для получения прогнозных оценок зависимой переменной подставим полученное значение независимой переменной в линейное уравнение:
5,07+2,14*42,24 = 304,55 млрд. руб.
Определим доверительный интервал прогноза, который будет иметь следующие границы:
Для вычисления доверительного интервала для прогнозного значения рассчитываем величину отклонения от линии регрессии.
Для модели парной регрессии величина отклонения рассчитывается:


т.е. значение стандартной ошибки из таблицы 1.5а.
(Так как число степеней свободы равно единицы, то знаменатель будет равен n-2). корреляция парная регрессия прогноз
Для расчета коэффициента воспользуемся функцией Excel СТЬЮДРАСПОБР, вероятность возьмем равную 0,1, число степеней свободы 38.
Значение рассчитаем с помощью Excel, получим 12294.

Определим верхнюю и нижнюю границы интервала.
- 304,55+27,472= 332,022
- 304,55-27,472= 277,078
Таким образом, прогнозное значение = 304,55 тыс.долл., будет находиться между нижней границей, равной 277,078 тыс.долл. и верхней границей, равной 332,022 млдр. Руб.
Фактические и модельные значения, точки прогноза представлены графически на рисунке 1.2.

Рисунок 1.2
6. Используя пошаговую множественную регрессию (метод исключения), построим модель формирования цены валового регионального продукта за счёт значимых факторов
Для построения множественной регрессии воспользуемся функцией Регрессия программы Excel, включив в нее все факторы. В результате получаем результативные таблицы, из которых нам необходим t-критерий Стьюдента.
Таблица 1.8а
Таблица 1.8б
Таблица 1.8в.
Получаем модель вида:
Поскольку < (4,75 < 71,024), уравнение регрессии следует признать адекватным.
Выберем наименьшее по модулю значение t-критерия Стьюдента, оно равно 8,427, сравниваем его с табличным значением, которые рассчитываем в Excel, уровень значимости берем равным 0,10, число степеней свободы n-m-1=12-4=8: =1,8595
Поскольку 8,427>1,8595 модель следует признать адекватной.
7. Для оценки значимого фактора полученной математической модели, рассчитаем коэффициенты эластичности, и - коэффициенты
Коэффициент эластичности показывает, насколько процентов изменится результативный признак при изменении факторного признака на 1%:
Э X4 = 2,137 *(10,69/24,182) = 0,94%
То есть с ростом инвестиции в основной капитал 1% стоимость в среднем возрастает на 0,94%.
Коэффициент показывает на какую часть величины среднего квадратического отклонения меняется среднее значение зависимой переменной с изменением независимой переменной на одно среднеквадратическое отклонение.
2,137* (14.736/33,632) = 0,936.
Данные средних квадратических отклонений взяты из таблиц, полученных с помощью инструменты Описательная статистика.
Таблица 1.11 Описательная статистика (Y)
Таблица 1.12 Описательная статистика (Х4)
Коэффициент определяет долю влияния фактора в суммарном влиянии всех факторов:
Для расчета коэффициентов парной корреляции вычисляем матрицу парных коэффициентов корреляции в программе Excel с помощью инструмента Корреляция настройки Анализа данных.
Таблица 1.14
(0,93633*0,93626) / 0,87 = 1,00.
Вывод: Из полученных расчетов можно сделать вывод, что результативный признак Y (валовой региональный продукт) имеет большую зависимость от фактора X1 (инвестиции в основной капитал) (на 100%).
Список литературы
- 1. Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. Учебное пособие. 2-е изд. - М.: Дело, 1998. - с. 69 - 74.
- 2. Практикум по эконометрике: Учебное пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др. 2002. - с. 49 - 105.
- 3. Доугерти К. Введение в эконометрику: Пер. с англ. - М.: ИНФРА-М, 1999. - XIV, с. 262 - 285.
- 4. Айвызян С.А., Михтирян В.С. Прикладная математика и основы эконометрики. -1998., с 115-147 .
- 5. Кремер Н.Ш., Путко Б.А. Эконометрика. -2007. с 175-251.
| - | y | x 1 | x 2 | x 3 |
| y | 1 | r yx1 | r yx2 | r yx3 |
| x 1 | r x1y | 1 | r x1x2 | r x1x3 |
| x 2 | r x2y | r x2x1 | 1 | r x2x3 |
| x 3 | r x3y | r x3x1 | r x3x2 | 1 |
Вставьте в поле матрицу парных коэффициентов.
Пример . По данным 154 сельскохозяйственных предприятий Кемеровской области 2003 г. изучить эффективность производства зерновых (табл. 13).
- Определите факторы, формирующие рентабельность зерновых в сельскохозяйственных предприятий в 2003 г.
- Постройте матрицу парных коэффициентов корреляции. Установите, какие факторы мультиколлинеарны.
- Постройте уравнение регрессии, характеризующее зависимость рентабельности зерновых от всех факторов.
- Оцените значимость полученного уравнения регрессии. Какие факторы значимо воздействуют на формирование рентабельности зерновых в этой модели?
- Оцените значение рентабельности производства зерновых в сельскохозяйственном предприятии № 3.
Решение получаем с помощью калькулятора Уравнение множественной регрессии :
1. Оценка уравнения регрессии.
Определим вектор оценок коэффициентов регрессии. Согласно методу наименьших квадратов, вектор получается из выражения:
s = (X T X) -1 X T Y
Матрица X
| 1 | 0.43 | 2.02 | 0.29 |
| 1 | 0.87 | 1.29 | 0.55 |
| 1 | 1.01 | 1.09 | 0.7 |
| 1 | 0.63 | 1.68 | 0.41 |
| 1 | 0.52 | 0.3 | 0.37 |
| 1 | 0.44 | 1.98 | 0.3 |
| 1 | 1.52 | 0.87 | 1.03 |
| 1 | 2.19 | 0.8 | 1.3 |
| 1 | 1.8 | 0.81 | 1.17 |
| 1 | 1.57 | 0.84 | 1.06 |
| 1 | 0.94 | 1.16 | 0.64 |
| 1 | 0.72 | 1.52 | 0.44 |
| 1 | 0.73 | 1.47 | 0.46 |
| 1 | 0.77 | 1.41 | 0.49 |
| 1 | 1.21 | 0.97 | 0.88 |
| 1 | 1.25 | 0.93 | 0.91 |
| 1 | 1.31 | 0.91 | 0.94 |
| 1 | 0.38 | 2.08 | 0.27 |
| 1 | 0.41 | 2.05 | 0.28 |
| 1 | 0.48 | 1.9 | 0.32 |
| 1 | 0.58 | 1.73 | 0.38 |
| 1 | 0 | 0 | 0 |
Матрица Y
| 0.22 |
| 0.67 |
| 0.79 |
| 0.42 |
| 0.32 |
| 0.24 |
| 0.95 |
| 1.05 |
| 0.99 |
| 0.96 |
| 0.73 |
| 0.52 |
| 2.1 |
| 0.58 |
| 0.87 |
| 0.89 |
| 0.91 |
| 0.14 |
| 0.18 |
| 0.27 |
| 0.37 |
| 0 |
Матрица X T
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 0.43 | 0.87 | 1.01 | 0.63 | 0.52 | 0.44 | 1.52 | 2.19 | 1.8 | 1.57 | 0.94 | 0.72 | 0.73 | 0.77 | 1.21 | 1.25 | 1.31 | 0.38 | 0.41 | 0.48 | 0.58 | 0 |
| 2.02 | 1.29 | 1.09 | 1.68 | 0.3 | 1.98 | 0.87 | 0.8 | 0.81 | 0.84 | 1.16 | 1.52 | 1.47 | 1.41 | 0.97 | 0.93 | 0.91 | 2.08 | 2.05 | 1.9 | 1.73 | 0 |
| 0.29 | 0.55 | 0.7 | 0.41 | 0.37 | 0.3 | 1.03 | 1.3 | 1.17 | 1.06 | 0.64 | 0.44 | 0.46 | 0.49 | 0.88 | 0.91 | 0.94 | 0.27 | 0.28 | 0.32 | 0.38 | 0 |
Умножаем матрицы, (X T X)
Находим определитель det(X T X) T = 34.35
Находим обратную матрицу (X T X) -1
| 0.6821 | 0.3795 | -0.2934 | -1.0118 |
| 0.3795 | 9.4402 | -0.133 | -14.4949 |
| -0.2934 | -0.133 | 0.1746 | 0.3204 |
| -1.0118 | -14.4949 | 0.3204 | 22.7272 |
Вектор оценок коэффициентов регрессии равен
s = (X T X) -1 X T Y =
| 0.1565 |
| 0.3375 |
| 0.0043 |
| 0.2986 |
Уравнение регрессии (оценка уравнения регрессии)
Y = 0.1565 + 0.3375X 1 + 0.0043X 2 + 0.2986X 3
Матрица парных коэффициентов корреляции
Число наблюдений n = 22. Число независимых переменных в модели ровно 3, а число регрессоров с учетом единичного вектора равно числу неизвестных коэффициентов. С учетом признака Y, размерность матрицы становится равным 5. Матрица, независимых переменных Х имеет размерность (22 х 5). Матрица Х T Х определяется непосредственным умножением или по следующим предварительно вычисленным суммам.Матрица составленная из Y и X
| 1 | 0.22 | 0.43 | 2.02 | 0.29 |
| 1 | 0.67 | 0.87 | 1.29 | 0.55 |
| 1 | 0.79 | 1.01 | 1.09 | 0.7 |
| 1 | 0.42 | 0.63 | 1.68 | 0.41 |
| 1 | 0.32 | 0.52 | 0.3 | 0.37 |
| 1 | 0.24 | 0.44 | 1.98 | 0.3 |
| 1 | 0.95 | 1.52 | 0.87 | 1.03 |
| 1 | 1.05 | 2.19 | 0.8 | 1.3 |
| 1 | 0.99 | 1.8 | 0.81 | 1.17 |
| 1 | 0.96 | 1.57 | 0.84 | 1.06 |
| 1 | 0.73 | 0.94 | 1.16 | 0.64 |
| 1 | 0.52 | 0.72 | 1.52 | 0.44 |
| 1 | 2.1 | 0.73 | 1.47 | 0.46 |
| 1 | 0.58 | 0.77 | 1.41 | 0.49 |
| 1 | 0.87 | 1.21 | 0.97 | 0.88 |
| 1 | 0.89 | 1.25 | 0.93 | 0.91 |
| 1 | 0.91 | 1.31 | 0.91 | 0.94 |
| 1 | 0.14 | 0.38 | 2.08 | 0.27 |
| 1 | 0.18 | 0.41 | 2.05 | 0.28 |
| 1 | 0.27 | 0.48 | 1.9 | 0.32 |
| 1 | 0.37 | 0.58 | 1.73 | 0.38 |
| 1 | 0 | 0 | 0 | 0 |
Транспонированная матрица.
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 0.22 | 0.67 | 0.79 | 0.42 | 0.32 | 0.24 | 0.95 | 1.05 | 0.99 | 0.96 | 0.73 | 0.52 | 2.1 | 0.58 | 0.87 | 0.89 | 0.91 | 0.14 | 0.18 | 0.27 | 0.37 | 0 |
| 0.43 | 0.87 | 1.01 | 0.63 | 0.52 | 0.44 | 1.52 | 2.19 | 1.8 | 1.57 | 0.94 | 0.72 | 0.73 | 0.77 | 1.21 | 1.25 | 1.31 | 0.38 | 0.41 | 0.48 | 0.58 | 0 |
| 2.02 | 1.29 | 1.09 | 1.68 | 0.3 | 1.98 | 0.87 | 0.8 | 0.81 | 0.84 | 1.16 | 1.52 | 1.47 | 1.41 | 0.97 | 0.93 | 0.91 | 2.08 | 2.05 | 1.9 | 1.73 | 0 |
| 0.29 | 0.55 | 0.7 | 0.41 | 0.37 | 0.3 | 1.03 | 1.3 | 1.17 | 1.06 | 0.64 | 0.44 | 0.46 | 0.49 | 0.88 | 0.91 | 0.94 | 0.27 | 0.28 | 0.32 | 0.38 | 0 |
Матрица A T A.
| 22 | 14.17 | 19.76 | 27.81 | 13.19 |
| 14.17 | 13.55 | 15.91 | 16.58 | 10.56 |
| 19.76 | 15.91 | 23.78 | 22.45 | 15.73 |
| 27.81 | 16.58 | 22.45 | 42.09 | 14.96 |
| 13.19 | 10.56 | 15.73 | 14.96 | 10.45 |
Полученная матрица имеет следующее соответствие:
Найдем парные коэффициенты корреляции.
Для y и x 1
Средние значения
Дисперсия
Коэффициент корреляции
Для y и x 2
Уравнение имеет вид y = ax + b
Средние значения
Дисперсия
Среднеквадратическое отклонение
Коэффициент корреляции
Для y и x 3
Уравнение имеет вид y = ax + b
Средние значения
Дисперсия
Среднеквадратическое отклонение
Коэффициент корреляции
Для x 1 и x 2
Уравнение имеет вид y = ax + b
Средние значения
Дисперсия
Среднеквадратическое отклонение
Коэффициент корреляции
Для x 1 и x 3
Уравнение имеет вид y = ax + b
Средние значения
Дисперсия
Среднеквадратическое отклонение
Коэффициент корреляции
Для x 2 и x 3
Уравнение имеет вид y = ax + b
Средние значения
Дисперсия
Среднеквадратическое отклонение
Коэффициент корреляции
Матрица парных коэффициентов корреляции.
| - | y | x 1 | x 2 | x 3 |
| y | 1 | 0.62 | -0.24 | 0.61 |
| x 1 | 0.62 | 1 | -0.39 | 0.99 |
| x 2 | -0.24 | -0.39 | 1 | -0.41 |
| x 3 | 0.61 | 0.99 | -0.41 | 1 |
Анализ первой строки этой матрицы позволяет произвести отбор факторных признаков, которые могут быть включены в модель множественной корреляционной зависимости. Факторные признаки, у которых r yxi < 0.5 исключают из модели.
Коллинеарность – зависимость между факторами. В качестве критерия мультиколлинеарности может быть принято соблюдение следующих неравенств:
r(x j y) > r(x k x j) ; r(x k y) > r(x k x j).
Если одно из неравенств не соблюдается, то исключается тот параметр x k или x j , связь которого с результативным показателем Y оказывается наименее тесной.
3. Анализ параметров уравнения регрессии.
Перейдем к статистическому анализу полученного уравнения регрессии: проверке значимости уравнения и его коэффициентов, исследованию абсолютных и относительных ошибок аппроксимации
Для несмещенной оценки дисперсии проделаем следующие вычисления:
Несмещенная ошибка e = Y - X*s (абсолютная ошибка аппроксимации)
| -0.18 |
| 0.05 |
| 0.08 |
| -0.08 |
| -0.12 |
| -0.16 |
| -0.03 |
| -0.24 |
| -0.13 |
| -0.05 |
| 0.06 |
| -0.02 |
| 1.55 |
| 0.01 |
| 0.04 |
| 0.04 |
| 0.03 |
| -0.23 |
| -0.21 |
| -0.15 |
| -0.1 |
| -0.16 |
s e 2 = (Y - X*s) T (Y - X*s)
Несмещенная оценка дисперсии равна
Оценка среднеквадратичного отклонения равна
Найдем оценку ковариационной матрицы вектора k = a*(X T X) -1
| 0.26 | 0.15 | -0.11 | -0.39 |
| 0.15 | 3.66 | -0.05 | -5.61 |
| -0.11 | -0.05 | 0.07 | 0.12 |
| -0.39 | -5.61 | 0.12 | 8.8 |
Дисперсии параметров модели определяются соотношением S 2 i = K ii , т.е. это элементы, лежащие на главной диагонали
С целью расширения возможностей содержательного анализа модели регрессии используются частные коэффициенты эластичности , которые определяются по формуле:
Частные коэффициент эластичности E 1 < 1. Следовательно, его влияние на результативный признак Y незначительно.
Частные коэффициент эластичности E 2 < 1. Следовательно, его влияние на результативный признак Y незначительно.
Частные коэффициент эластичности E 3 < 1. Следовательно, его влияние на результативный признак Y незначительно.
Тесноту совместного влияния факторов на результат оценивает индекс множественной корреляции (от 0 до 1)
Связь между признаком Y факторами X умеренная
Коэффициент детерминации
R 2 = 0.62 2 = 0.38
т.е. в 38.0855 % случаев изменения х приводят к изменению y. Другими словами - точность подбора уравнения регрессии - средняя
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
T табл (n-m-1;a) = (18;0.05) = 1.734
Поскольку Tнабл > Tтабл, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически - значим
Интервальная оценка для коэффициента корреляции (доверительный интервал)
Доверительный интервал для коэффициента корреляции
r(0.3882;0.846)
5. Проверка гипотез относительно коэффициентов уравнения регрессии (проверка значимости параметров множественного уравнения регрессии).
1) t-статистика
Статистическая значимость коэффициента регрессии b 0 не подтверждается
Статистическая значимость коэффициента регрессии b 1 не подтверждается
Статистическая значимость коэффициента регрессии b 2 не подтверждается
Статистическая значимость коэффициента регрессии b 3 не подтверждается
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b i - t i S i ; b i + t i S i)
b 0: (-0.7348;1.0478)
b 1: (-2.9781;3.6531)
b 2: (-0.4466;0.4553)
b 3: (-4.8459;5.4431)
2) F-статистика. Критерий Фишера
Fkp = 2.93
Поскольку F < Fkp, то коэффициент детерминации статистически не значим и уравнение регрессии статистически ненадежно.
6. Проверка на наличие гетероскедастичности методом графического анализа остатков.
В этом случае по оси абсцисс откладываются значения объясняющей переменной X i , а по оси ординат квадраты отклонения e i 2 .
| y | y(x) | e=y-y(x) | e 2 |
| 0.22 | 0.4 | -0.18 | 0.03 |
| 0.67 | 0.62 | 0.05 | 0 |
| 0.79 | 0.71 | 0.08 | 0.01 |
| 0.42 | 0.5 | -0.08 | 0.01 |
| 0.32 | 0.44 | -0.12 | 0.02 |
| 0.24 | 0.4 | -0.16 | 0.03 |
| 0.95 | 0.98 | -0.03 | 0 |
| 1.05 | 1.29 | -0.24 | 0.06 |
| 0.99 | 1.12 | -0.13 | 0.02 |
| 0.96 | 1.01 | -0.05 | 0 |
| 0.73 | 0.67 | 0.06 | 0 |
| 0.52 | 0.54 | -0.02 | 0 |
| 2.1 | 0.55 | 1.55 | 2.41 |
| 0.58 | 0.57 | 0.01 | 0 |
| 0.87 | 0.83 | 0.04 | 0 |
| 0.89 | 0.85 | 0.04 | 0 |
| 0.91 | 0.88 | 0.03 | 0 |
| 0.14 | 0.37 | -0.23 | 0.05 |
| 0.18 | 0.39 | -0.21 | 0.04 |
| 0.27 | 0.42 | -0.15 | 0.02 |
| 0.37 | 0.47 | -0.1 | 0.01 |
| 0.16 | -0.16 | 0.02 |
Анализ матрицы парных коэффициентов корреляции показывает, что результативный показатель наиболее тесно связан с показателем x (4) - количество удобрений, расходуемых на 1 га ().
В то же время
связь между признаками-аргументами
достаточно тесная. Так, существует
практически функциональная связь между
числом колесных тракторов (x
(1))
и числом орудий поверхностной обработки
почвы .
.
О наличии
мультиколлинеарности свидетельствуют
также коэффициенты корреляции
 и
и .
Учитывая тесную взаимосвязь показателейx
(1) , x
(2) и x
(3) ,
в регрессионную модель урожайности
может войти лишь один из них.
.
Учитывая тесную взаимосвязь показателейx
(1) , x
(2) и x
(3) ,
в регрессионную модель урожайности
может войти лишь один из них.
Чтобы продемонстрировать отрицательное влияние мультиколлинеарности, рассмотрим регрессионную модель урожайности, включив в нее все исходные показатели:

 F набл
= 121.
F набл
= 121.
В скобках
указаны значения исправленных оценок
среднеквадратических отклонений оценок
коэффициентов уравнения
 .
.
Под уравнением
регрессии представлены следующие его
параметры адекватности: множественный
коэффициент детерминации
 ;
исправленная оценка остаточной дисперсии
;
исправленная оценка остаточной дисперсии ,
средняя относительная ошибка аппроксимациии расчетное значение-критерия
F набл = 121.
,
средняя относительная ошибка аппроксимациии расчетное значение-критерия
F набл = 121.
Уравнение регрессии значимо, т.к. F набл = 121 > F kp = 2,85 найденного по таблицеF -распределения при=0,05; 1 =6 и 2 =14.
Из этого следует, что 0, т.е. и хотя бы один из коэффициентов уравнения j (j = 0, 1, 2, ..., 5) не равен нулю.
Для проверки
гипотезы о значимости отдельных
коэффициентов регрессии H0: j =0,
гдеj
=1,2,3,4,5, сравнивают критическое
значениеt
kp = 2,14, найденное по
таблицеt
-распределения при уровне
значимости=2Q
=0,05
и числе степеней свободы=14,
с расчетным значением .
Из уравнения следует, что статистически
значимым является коэффициент регрессии
только при x
(4) , так какt
4 =2,90
>t
kp =2,14.
.
Из уравнения следует, что статистически
значимым является коэффициент регрессии
только при x
(4) , так какt
4 =2,90
>t
kp =2,14.
Не поддаются экономической интерпретации отрицательные знаки коэффициентов регрессии при x (1) и x (5) . Из отрицательных значений коэффициентов следует, что повышение насыщенности сельского хозяйства колесными тракторами (x (1)) и средствами оздоровления растений (x (5)) отрицательно сказывается на урожайности. Таким образом, полученное уравнение регрессии неприемлемо.
Для получения уравнения регрессии со значимыми коэффициентами используем пошаговый алгоритм регрессионного анализа. Первоначально используем пошаговый алгоритм с исключением переменных.
Исключим из модели переменную x (1) , которой соответствует минимальное по абсолютной величине значениеt 1 =0,01. Для оставшихся переменных вновь построим уравнение регрессии:
Полученное уравнение значимо, т.к. F набл = 155 > F kp = 2,90, найденного при уровне значимости=0,05 и числах степеней свободы 1 =5 и 2 =15 по таблицеF -распределения, т.е. вектор0. Однако в уравнении значим только коэффициент регрессии приx (4) . Расчетные значенияt j для остальных коэффициентов меньшеt кр = 2,131, найденного по таблицеt -распределения при=2Q =0,05 и=15.
Исключив из модели переменную x (3) , которой соответствует минимальное значениеt 3 =0,35 и получим уравнение регрессии:
 (2.9)
(2.9)
В полученном уравнении статистически не значим и экономически не интерпретируем коэффициент при x (5) . Исключивx (5) получим уравнение регрессии:
 (2.10)
(2.10)
Мы получили значимое уравнение регрессии со значимыми и интерпретируемыми коэффициентами.
Однако полученное уравнение является не единственно “хорошей” и не “самой лучшей” моделью урожайности в нашем примере.
Покажем, что в условии мультиколлинеарности пошаговый алгоритм с включением переменных является более эффективным. На первом шаге в модель урожайностиy входит переменная x (4) , имеющая самый высокий коэффициент корреляции сy , объясняемой переменнойr (y , x (4))=0,58. На втором шаге, включая уравнение наряду сx (4) переменныеx (1) илиx (3) , мы получим модели, которые по экономическим соображениям и статистическим характеристикам превосходят (2.10):
 (2.11)
(2.11)
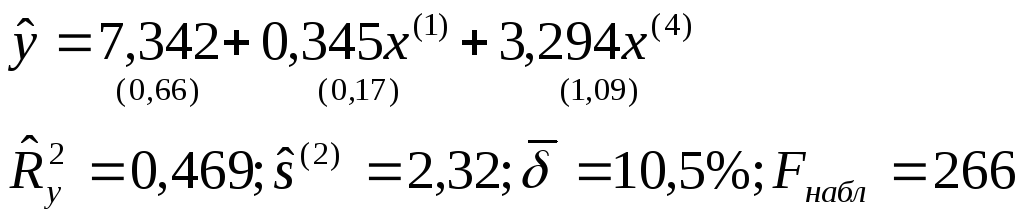 (2.12)
(2.12)
Включение в уравнение любой из трех оставшихся переменных ухудшает его свойства. Смотри, например, уравнение (2.9).
Таким образом, мы имеем три “хороших” модели урожайности, из которых нужно выбрать по экономическим и статистическим соображениям одну.
По статистическим
критериям наиболее адекватна модель
(2.11). Ей соответствуют минимальные
значения остаточной дисперсии
 =2,26
и средней относительной ошибки
аппроксимациии наибольшие значения
=2,26
и средней относительной ошибки
аппроксимациии наибольшие значения и F набл = 273.
и F набл = 273.
Несколько худшие показатели адекватности имеет модель (2.12), а затем - модель (2.10).
Будем теперь выбирать наилучшую из моделей (2.11) и (2.12). Эти модели отличаются друг от друга переменными x (1) иx (3) . Однако в моделях урожайностей переменнаяx (1) (число колесных тракторов на 100 га) более предпочтительна, чем переменнаяx (3) (число орудий поверхностной обработки почвы на 100 га), которая является в некоторой степени вторичной (или производной от x (1)).
В этой связи из экономических соображений предпочтение следует отдать модели (2.12). Таким образом, после реализации алгоритма пошагового регрессионного анализа с включением переменных и учета того, что в уравнение должна войти только одна из трех связанных переменных (x (1) ,x (2) илиx (3)) выбираем окончательное уравнение регрессии:

Уравнение
значимо при =0,05,
т.к. F набл = 266 > F kp = 3,20,
найденного по таблицеF
-распределения
при=Q
=0,05; 1 =3
и 2 =17. Значимы
и все коэффициенты регрессии и
и в уравненииt
j >t
kp (=2Q
=0,05;=17)=2,11. Коэффициент
регрессии 1 следует признать значимым ( 1 0)
из экономических соображений, при этомt
1 =2,09 лишь незначительно меньшеt
kp = 2,11.
в уравненииt
j >t
kp (=2Q
=0,05;=17)=2,11. Коэффициент
регрессии 1 следует признать значимым ( 1 0)
из экономических соображений, при этомt
1 =2,09 лишь незначительно меньшеt
kp = 2,11.
Из уравнения регрессии следует, что увеличение на единицу числа тракторов на 100 га пашни (при фиксированном значении x (4)) приводит к росту урожайности зерновых в среднем на 0,345 ц/га.
Приближенный расчет коэффициентов эластичности э 1 0,068 и э 2 0,161 показывает, что при увеличении показателейx (1) иx (4) на 1% урожайность зерновых повышается в среднем соответственно на 0,068% и 0,161%.
Множественный
коэффициент детерминации
 свидетельствует о том, что только 46,9%
вариации урожайности объясняется
вошедшими в модель показателями (x
(1) иx
(4)), то есть насыщенностью
растениеводства тракторами и удобрениями.
Остальная часть вариации обусловлена
действием неучтенных факторов (x
(2) ,x
(3) ,x
(5) , погодные
условия и др.). Средняя относительная
ошибка аппроксимациихарактеризует адекватность модели, так
же как и величина остаточной дисперсии
свидетельствует о том, что только 46,9%
вариации урожайности объясняется
вошедшими в модель показателями (x
(1) иx
(4)), то есть насыщенностью
растениеводства тракторами и удобрениями.
Остальная часть вариации обусловлена
действием неучтенных факторов (x
(2) ,x
(3) ,x
(5) , погодные
условия и др.). Средняя относительная
ошибка аппроксимациихарактеризует адекватность модели, так
же как и величина остаточной дисперсии .
При интерпретации уравнения регрессии
интерес представляют значения
относительных ошибок аппроксимации
.
При интерпретации уравнения регрессии
интерес представляют значения
относительных ошибок аппроксимации .
Напомним, что
.
Напомним, что -
модельное значение результативного
показателя, характеризует среднее для
совокупности рассматриваемых районов
значение урожайности при условии, что
значения объясняющих переменныхx
(1) иx
(4) зафиксированы на одном
и том же уровне, а именноx
(1) =x
i
(1) иx
(4)
= x
i
(4) . Тогда по значениям i
можно
сопоставлять районы по урожайности.
Районы, которым соответствуют значения i
>0, имеют
урожайность выше среднего, а i
<0
- ниже среднего.
-
модельное значение результативного
показателя, характеризует среднее для
совокупности рассматриваемых районов
значение урожайности при условии, что
значения объясняющих переменныхx
(1) иx
(4) зафиксированы на одном
и том же уровне, а именноx
(1) =x
i
(1) иx
(4)
= x
i
(4) . Тогда по значениям i
можно
сопоставлять районы по урожайности.
Районы, которым соответствуют значения i
>0, имеют
урожайность выше среднего, а i
<0
- ниже среднего.
В нашем примере, по урожайности наиболее эффективно растениеводство ведется в районе, которому соответствует 7 =28%, где урожайность на 28% выше средней по региону, и наименее эффективно - в районе с 20 =27,3%.